
Table Of Contents


Now, in Part II, we roll up our sleeves and delve into the technical aspects that form the backbone of your software projects. Just as a gardener prepares the ground, selects the right seeds, and tends to the garden, we’ll guide you through setting up your projects for success. Version control, coding styles, conventions, and merge strategies are the tools of your trade in this journey. By mastering these elements, you’ll ensure that your project not only takes root but also flourishes into a robust and efficient software endeavor.
Establishing Effective Team Standards
Building software is a journey through complexity, and when multiple minds come together to work on a project, a new layer of complexity arises: team dynamics. People bring their unique perspectives, work styles, and opinions on code quality and style. Ensuring that everyone is on the same page from the outset is crucial for a smooth project journey. Without clear rules and standards, unresolved interpersonal conflicts can derail even the most promising project.
Setting the rules of the game within a team can be a delicate task, but it’s a fundamental step toward project success. There are several approaches to reaching a consensus:
Dictate the Rules: In some situations, especially in larger organizations, a top-down approach may be necessary to maintain consistent quality standards. This approach leaves little room for debate and is often the fastest way to set rules. However, it can stifle learning and hinder opportunities for continuous improvement at scale.
Majority Vote: Democracy in action. Majority rule can lead to quick decisions, but it’s important to note that popularity doesn’t always equate to the best choice. The loudest opinions may overshadow more thoughtful ones, potentially leading to suboptimal decisions and limited acceptance of the established rules.
Dialectic Reasoning: This method involves reaching an agreement through a thoughtful exploration of different viewpoints and reasoned argumentation. While it may take more time, it fosters an environment where everyone has a say, encourages new insights, and ultimately results in rules that the team fully accepts.
In my opinion, you should always strive to create an environment where you reach agreements through dialectic reasoning. Yes, it can be time-consuming, but your project will benefit in the long run by addressing conflicting opinions early in the process. Without acceptance of the rules of the game, trust quickly erodes, and no matter how good your technical setup is, without trust between team members, every project will stall.
Moreover, dialectic reasoning isn’t just about setting rules; it’s a constant source of growth and improvement. Just as a gardener learns from each season’s successes and challenges, a team that engages in meaningful discussions continually refines its processes and standards.
So, consider these recommendations as seeds of inspiration for your team’s unique garden, where the rules are designed to nurture a thriving and collaborative environment.
Version Control Systems: The Backbone of Your Project
In the world of software development, version control systems (VCS) are the unsung heroes, with Git being the undisputed industry standard. Having a VCS in your project brings three significant advantages:
- A Safety Net for Solo Developers: For solo developers or those working on personal projects, a VCS acts as a safety net, allowing you to journey back in time and revert changes. This safety net encourages risk-taking and experimentation, fostering innovation and growth.
- Seamless Collaboration for Teams: From a team perspective, a VCS is invaluable. It empowers teams to manage a shared codebase effortlessly, preventing conflicts and simplifying conflict resolution. Collaboration becomes smoother and more efficient.
- Project Management Made Easier: For project managers, a VCS serves as a window into the codebase, offering insights into what has been accomplished. It aids in setting up workflows that ensure quality and promote collaboration among team members.
While many of you may already be well acquainted with Git, we understand that some readers may be new to this powerful version control system or may appreciate a refresher. For the latter group and those looking to strengthen their Git skills, here are some fundamental topics to delve into:
- Understanding Git’s distributed nature: Grasping the concept of remotes, which enable collaboration across different locations
- The three stages: Untracked, Staged, and Committed: Learning how Git tracks changes and moves code through these stages
- Branching, Merging, and Rebasing: Exploring essential Git workflows for managing code branches and integrating changes.
- Leveraging Pull Requests: Understanding how Pull Requests facilitate code review and collaboration within Git repositories.
- The Art of Rewriting History: Exploring advanced Git techniques, such as rebasing and force pushing, to reshape commit history.
While we won’t delve into exhaustive Git tutorials here, there are excellent resources available online to deepen your Git knowledge. One highly recommended source is the video series by Scott Hanselman:
- Git 101 Basics - Computer Stuff They Didn’t Teach You #4
- Git Pull Requests explained - Computer Stuff They Didn’t Teach You #5
- Git Rebase vs Merge explained - Computer Stuff They Didn’t Teach You #6
- Git Push —Force will destroy the timeline and kill us all - Computer Stuff They Didn’t Teach You #7
Additionally, for an interactive and visual way to learn Git commands, check out the game Learn Git Branching.
Lastly, Git shines with text files, but can be challenged by binary assets like images or videos. To keep your repository efficient, consider setting up Git LFS (Large File Storage) for handling large binary assets effectively.
A Closer Look at Branching Strategies
Have you ever encountered projects with a main branch and a development branch, where most of the work eventually finds its way into the development branch? In many cases, I’ve observed that development branches can unintentionally introduce a layer of systematic procrastination, often leading to a delay in real integration work. Additionally, this approach can inadvertently foster the philosophy of deploying the main branch for production while treating the development branch as a playground where subpar quality is deemed acceptable.
My recommendation here is to rethink the notion of development branches. Instead, consider adopting a feature branch approach and prioritizing swift integration into the main branch. By doing so, you’ll ensure that deployments are based on specific commits rather than branches, streamlining your development workflow.
Managing Unnecessary Files with .gitignore
When you kickstart your repository, one of the initial tasks is to craft a .gitignore file tailored specifically to your project’s needs. This file is your ally in ensuring that only the essential files are tracked by the version control system, keeping your repository clean and efficient. It’s essential to exclude certain types of files from being included in the VCS. These may include build artifacts, temporary files, and editor-specific configurations, as they often clutter the repository without adding value. Additionally, sensitive information, such as credentials stored in .env files, should never be committed.
To make the process of generating a .gitignore file more straightforward, I’ve personally found Toptal’s gitignore generator to be a valuable tool. It allows you to select multiple languages and frameworks, ensuring that your .gitignore file is comprehensive and tailored to your project’s technology stack.
Coding styles and conventions
Maintaining consistency within a codebase is paramount for reducing cognitive overhead and ensuring ease of maintenance. This becomes even more critical when collaborating within a team, where a shared coding style becomes the linchpin for comprehending a collective codebase.
My recommendation in this regard is simple: don’t reinvent the wheel. Instead, adopt coding styles and conventions that are widely embraced, either by prominent organizations or endorsed by the creators of a language or framework. For instance, consider Google’s Style Guide for various languages, Apple’s Swift Style Guide, or Effective Dart for Dart and Flutter projects.
However, adhering to coding styles is just one piece of the puzzle. Equally important is providing prompt feedback on style violations, and this is where a linter, or code linter, comes into play.
The primary role of a linter is to enforce coding standards, enhance code readability, and catch errors at the earliest stages of development. It should seamlessly integrate into your integrated development environment (IDE), offering real-time feedback as you write code.
Now, it’s no secret that developers may not always relish the idea of cleaning up their code. They might be inclined to overlook warnings generated by linters, allowing them to accumulate over time. This can lead to significant warnings getting lost in a sea of clutter. To counter this, consider configuring the linter to treat warnings as errors. In other words, no more benign yellow squiggly lines highlighting code convention violations; it’s the red lines that demand attention. This approach, based on my experience, encourages developers to maintain a pristine and orderly codebase, as it removes the option to dismiss code style violations.
While enforcing code conventions with a linter can also occur during continuous integration, the optimal strategy is to implement it as early as possible in the development process. This approach not only saves time but also minimizes frustration. The key here is to minimize the feedback loop for developers to become aware of code violations, thereby accelerating the iteration speed.
Merge Strategy with Rebase and Squash: Keeping History Clean
When it comes to integrating changes into the main branch, various merge strategies exist, and I ardently advocate for a Rebase strategy with squashed commits. But why this approach?
I firmly believe that a Git history should function as high-level documentation, providing immediate clarity about what has been accomplished and when. It shouldn’t be cluttered with every minuscule commit detail, but it should offer project managers a quick overview of development progress. This means maintaining a clear history with well-defined semantic commits on the main branch.

This approach might seem a tad daring because it involves using the ”force” (force commits) to rewrite history. Let’s delve deeper into this process with a scenario: Imagine the development on a feature branch is complete, and everything is ready for a Pull Request to integrate the work into the main branch. The work on the feature branch has resulted in numerous commits, some with less-than-stellar commit messages.
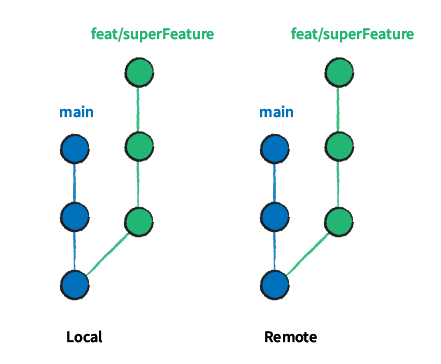
Before opening a Pull Request to merge this work into the main branch, the first step is to squash all those commits.
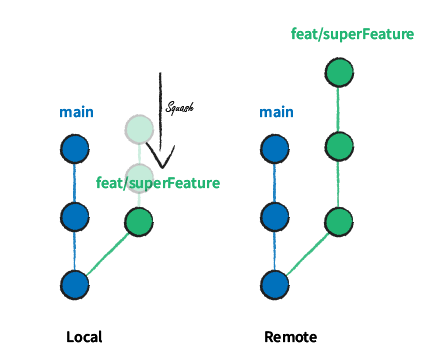
Next, rebase the feature branch on top of the main branch.
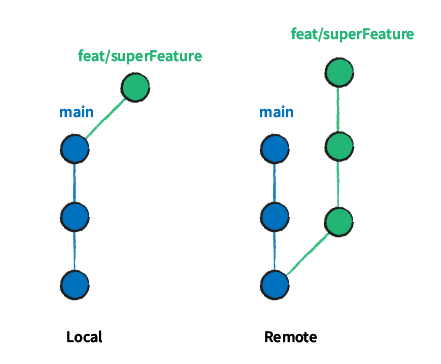

This strategy ensures that the main branch’s history remains pristine, containing only the essential elements of the work performed.
Semantic Commit Messages
One thing that I left out before was the quality of the commit message for the Pull Request. In order to make them meaningful, consistent, and human-readable, I strongly advise using semantic commit messages.
They follow a structured format, where the type is followed by a colon and a summary in the present tense, making it clear and concise. These types help team members quickly understand the purpose and context of each commit, making collaboration and code review more efficient.
Semantic commit messages look like this:
feat: add hat wobble^--^ ^------------^| || +-> Summary in present tense.|+-------> Type: chore, docs, feat, fix, refactor, style, or test.
- feat: This type represents a “feature” commit. It is used when you introduce a new functionality or feature into the codebase. For example, adding a new user registration system would be labeled as a feat commit.
- fix: When you make changes to address and resolve a bug or issue in the code, you use the fix type. It indicates that the commit contains bug fixes that correct problems in the software.
- docs: The docs type is for documentation-related commits. Whenever you update or create documentation, such as README files, comments, or user guides, you would use this type. It helps in keeping track of changes made to documentation.
- style: Style-related changes that do not impact the actual code functionality fall under the style type. This includes formatting adjustments, adding or fixing code comments, or ensuring consistent coding style without affecting how the program works.
- refactor: The refactor type is used when you make code changes to improve its structure, readability, or maintainability. It typically involves code modifications that don’t change the software’s external behavior but enhance its internal structure.
- test: When you work on tests, such as adding new tests, enhancing existing ones, or improving test-related code, you use the test type. This ensures that testing-related changes are easily distinguishable.
- chore: The chore type is reserved for tasks related to code maintenance, tooling, or project setup. It encompasses non-code changes like updating build scripts, configuring development tools, or performing routine project maintenance tasks.
For more information about semantic commits check out the Conventional Commits specification.
Summary
In this part, we have explored essential steps to ensure a smooth project setup, encompassing aspects like version control, coding styles, merge strategies and semantic commit messages.
In the forthcoming segment, we will explore more advanced techniques to maintain high-quality standards during product delivery. Topics will include establishing quality gates through Continuous Integration, conducting effective code reviews, and optimizing issue tracking for efficiency.
Stay tuned for further insights on building and managing successful software projects.
Related Posts
Quick Links
Legal Stuff